Size Matters But Not in the
Way You Think
There is the old adage that size matters. Whether people are talking about how big someone’s car is (implying a certain status) or how tall the office building being leased is, society often gets a little too hung up on the perception of size and its relation to how “good” things are.

Table of Contents
The Data Game
When it comes to data, and data management, the size of one’s database is not always a fair indicator of accuracy. Many different factors make up a reliable database, and often (if not always) the challenge is trying to strike that balance between quantity and quality.
In the data game, data owners put tremendous efforts into maintaining their respective datasets, employing a whole raft of validation procedures to keep the data in check. Being able to leverage a reliable source of public data is always key, but having an effective data pooling program in place, whereby many contribute to a single source, allows for the error rate of validations to be negated.
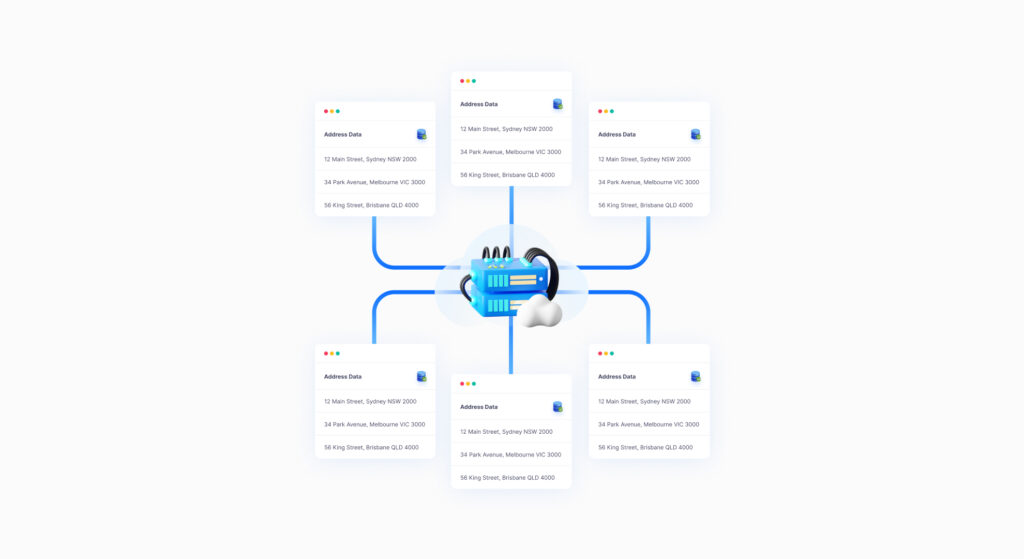
Example: Data Pooling Program.
A data pooling program is when multiple contributors adding their data to a single, centralized source. it allows for cross-verification and validation. For instance, if multiple sources provide similar data, it can increase confidence in its accuracy. Additionally, pooling can involve sophisticated algorithms and checks to clean, match, and integrate data, reducing errors that might exist in isolated datasets.
Realistically, there’s no way for any company to think that they’ve got information that nobody else does. In this day and age, businesses don’t win by having the most information in your database. They win when they can rely on that customer information to provide ancillary knowledge for each individual.
Examples of this include sales history, campaign responses, and personal facts that may have been shared during a phone conversation.
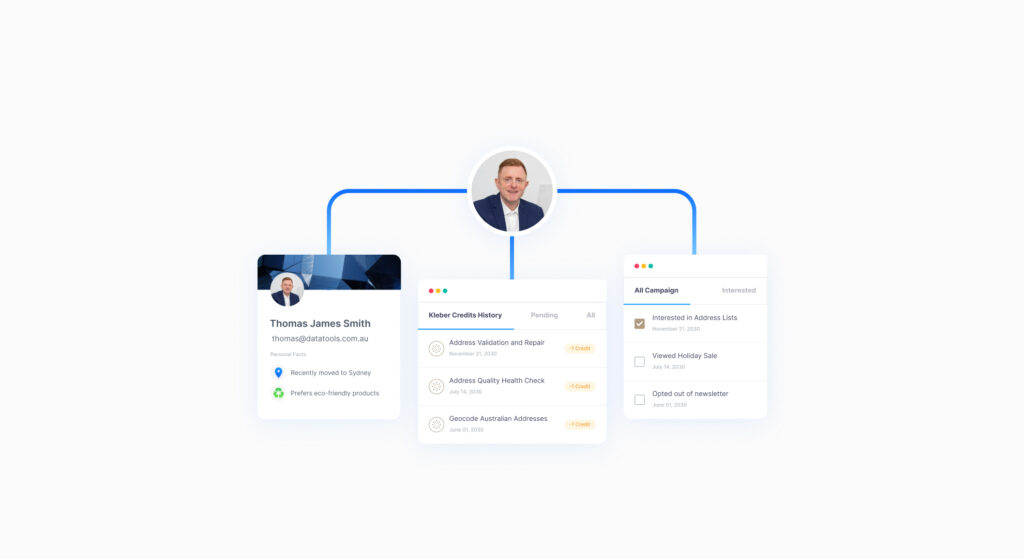
Database example revealing a customers history and activities.
This information will help maintain effective rapport throughout the business relationship. After all, it’s always nice to talk to someone who seems to remember all the important details of previous conversations. It is here that an effective data management team can ensure that the right information is available to the Sales and Marketing teams as they need it.
And if a company buys and imports third party lists into their database, then data management becomes doubly critical. These lists may have been purchased under the assumption that they are from a particular industry sector, or that they have a certain interest (newborn babies, for example). If so, then any matches that can be made to the existing database can yield more information. This is true for both the campaign the data was purchased for as well as for the company’s existing database.
Unfortunately, matching to an existing database isn’t always so straightforward and often, things can quickly go downhill:
- Differing Data Formats: The format of data in third-party lists often varies from the existing database, creating alignment issues.
- Data Quality Variability: These lists may contain outdated or inaccurate information, complicating the matching process.
- Duplication Risks: Integrating new data runs the risk of creating duplicate records, which can be tricky to identify and resolve without sophisticated tools.
So, what kind of software could rise to the challenge?
For large, once off data sets, it would be nice to have a tool that could automate essential data processing tasks, such as sorting and updating files, with simple notepad edits. Something that could process more than 100,000 records in less than five minutes on a standard PCs, eliminating the need to invest in expensive and specialised hardware.
This solution would not only be cost-effective, enhancing existing systems without a significant investment, but also versatile. It would handle unlimited data sizes and fields and be compatible with various reporting tools for tailored reporting needs.
All these capabilities are encapsulated in DataTools File Processing Command (FPC), a powerful yet user-friendly tool that transforms the complexity of data integration into a streamlined, efficient process.
Alternatively, other businesses may also need a reliable solution that can regularly perform matching and other related tasks on their database. Our flagship product, DataTools Kleber, would be a more suitable alternative in this scenario.
The Data Game
DataTools Kleber is a cloud-based API offering advanced data matching and address validation capabilities. It represents the modern shift in data management, providing powerful, scalable, and accessible tools for today’s digitally-driven businesses.
Just remember, always compare apples with apples. This means that when running newly bought data through FPC, the existing database must have gone through the same treatment as well. This way, the information is verified to have come from the same place and the same logic has been applied to it. This way, you’re ensuring that the information has come from the same place, and the same logic has been applied to it.
So, the next time a discussion on “how big it is” comes up…remember that it’s never just about the size. Data quality, time spent on maintenance, and effort to ensure accuracy is equally important too.