
Facebook IPO 2012
Facebook’s IPO in 2012 is a good example of what happens when hope exceeds expectation. Back then, the hype reached fever-pitch levels. Both investors and the media were caught up in heavy speculation and sky-high valuations. After an incredible buildup and rush to invest on the first day, the share price did not take off as expected, leading many to question the company’s future earnings and capacity to succeed with mobile users.
We observed the hysteria back then and found it similar to observing the expectations from upper management when new data is bought, without any care or comparison to what is already contained within the existing dataset.
The allure of potential can often overshadow practical realities – ones where the results desired call for rigorous evaluation, integration, and expertise.
And unfortunately, we’ve seen that happen far too many times. Some of our team members have been in the game since the days of dial-up and floppy disks – way before Facebook was even in the market! We became so jaded with buying new data sets that it reached a point where we just didn’t care about anything new coming in until we were actually able to verify and quantify the lift it would bring personally.
When new data is brought into a system, it is accompanied by new challenges and responsibilities. You need to worry about how all this information is going to fit into your team’s existing data structures and processes. You need to find out if it’s accurate data that you can use to verify a customer’s identity, deliver parcels, run compliance checks, or add to your loyalty program.
The list goes on and on – as long as you are dealing with customer information, you need to think about its integration, validation, and maintenance.
That being said, we need to ensure consistency with what we’ve already worked on. We need to make sure that we’re clear on the source, the recency, and finally the accuracy of the data.
And when it comes to securing that consistency, you’ll need a specialist or a software that can:
- Make sure all data is parsed in the same manner
- Verify that all address points are in a uniform format
- Conform to Australia Post standards (a bit of a bonus at this point!)
It’s a big job! In some cases, it may be the reason why you find it difficult to scale or manage your activities. Faulty data is the reason you’re spending so much time on failed deliveries, poor ROI on marketing campaigns, pricey logistics, and more.
To achieve and maintain high data quality, you’ll need a data specialist or advanced software. You can only say for certain that your database is reaping long term benefits for your business when the wins are quantifiable, and when you have a highly accurate, profitable dataset.
In the dynamic realm of data management, the story of Facebook’s IPO is a telling reminder that the excitement of potential must be grounded in reality. Much like stakeholders in 2012, businesses today face the challenge of matching the promise of new data with its actual performance and integration within existing systems.
This is where Kleber steps into the spotlight.
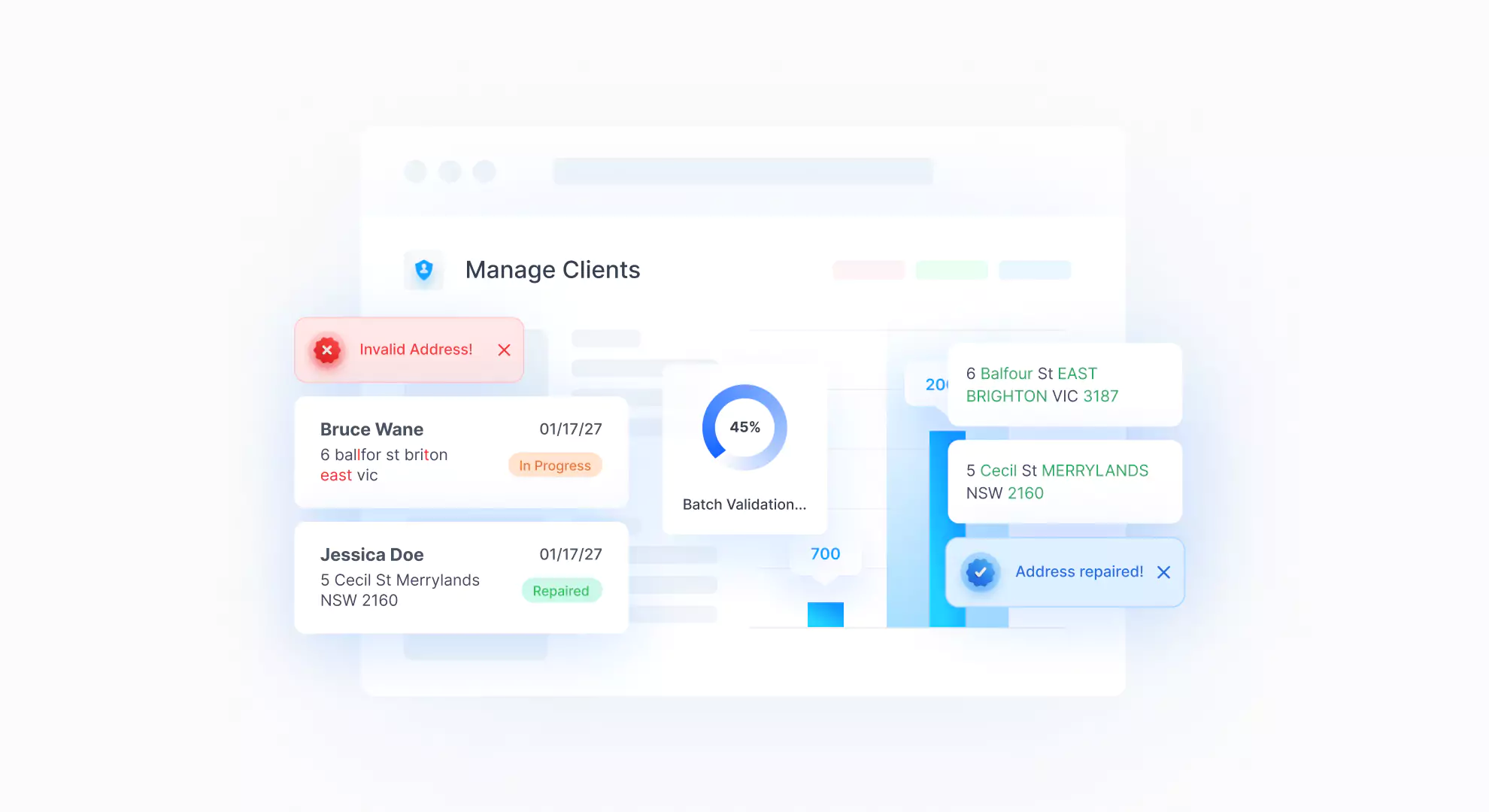
DataTools software batch validating CRM addresses.
Kleber by DataTools
With Kleber’s simple single API integration, the chaos of mismatched formats and manual parsing become things of the past. Kleber validates and repairs your data in real-time, aligning new information with your established data sets seamlessly.
Imagine a world where every piece of data is immediately shaped to fit your precise needs, where address points are uniform, and compliance with Australia Post is not just a bonus but a guarantee. Kleber makes this your reality, turning potential into performance, hope into tangible outcomes.