Why CRM Copycats Spell Catastrophe for Business
The main reason duplicates exist is because often, multiple data sets are used to create a single repository of information. We may be sourcing these data sets from purchased lists, web-based data and data from inbound leads. Once everything is combined, some leads will have been imported from more than one source.
So, why care about duplicates? It’s ugly, wasteful and gives you the wrong impression about your database. If we have duplicate data, we make twice or thrice the work and expenses for no monetary gain. And it’s not just sucking away resources – duplicates can also make a business seem unprofessional.
Maybe it’s just us being data geeks, but if a business can’t manage its own data, then how well can it really handle our needs?
Organisations that care about their data can take a number of different steps to remove duplicates from their system. There are several front-end applications for rudimentary de-duplication when importing data, like excluding records based on a phone number or an address. For some businesses, this is all they need to keep their database clean.
However, we’ve found that this approach is too basic for most businesses. If people need de-duplication, then they won’t just be looking for something that can spot the most obvious duplicates, but also find dupes that are impossible to see through normal channels. For this purpose, DataTools Kleber is a convenient cloud-based API that can help validate and remove duplicates as needed.
For example:
Most businesses have a database of customers and prospects. These two data sets may be in distinct tables, systems, or just labelled within the record. At some point, the business owner or manager may want to generate additional long-term revenue, so they start a mailout acquisition campaign to increase their customer base.
This campaign is usually something basic, just to entice people to get onboard; time sensitive in nature and has enticements embedded into the offer that are purely to acquire additional customers.
Time-sensitive campaigns like these, with special incentives, are great for attracting new customers but not cost-effective for existing ones. Each mailed offer costs at least $1.50, plus extra for the incentive and handling. So, if you have a clean, duplicate-free database, you can make sure these offers only reach potential new customers and avoid wasted costs.
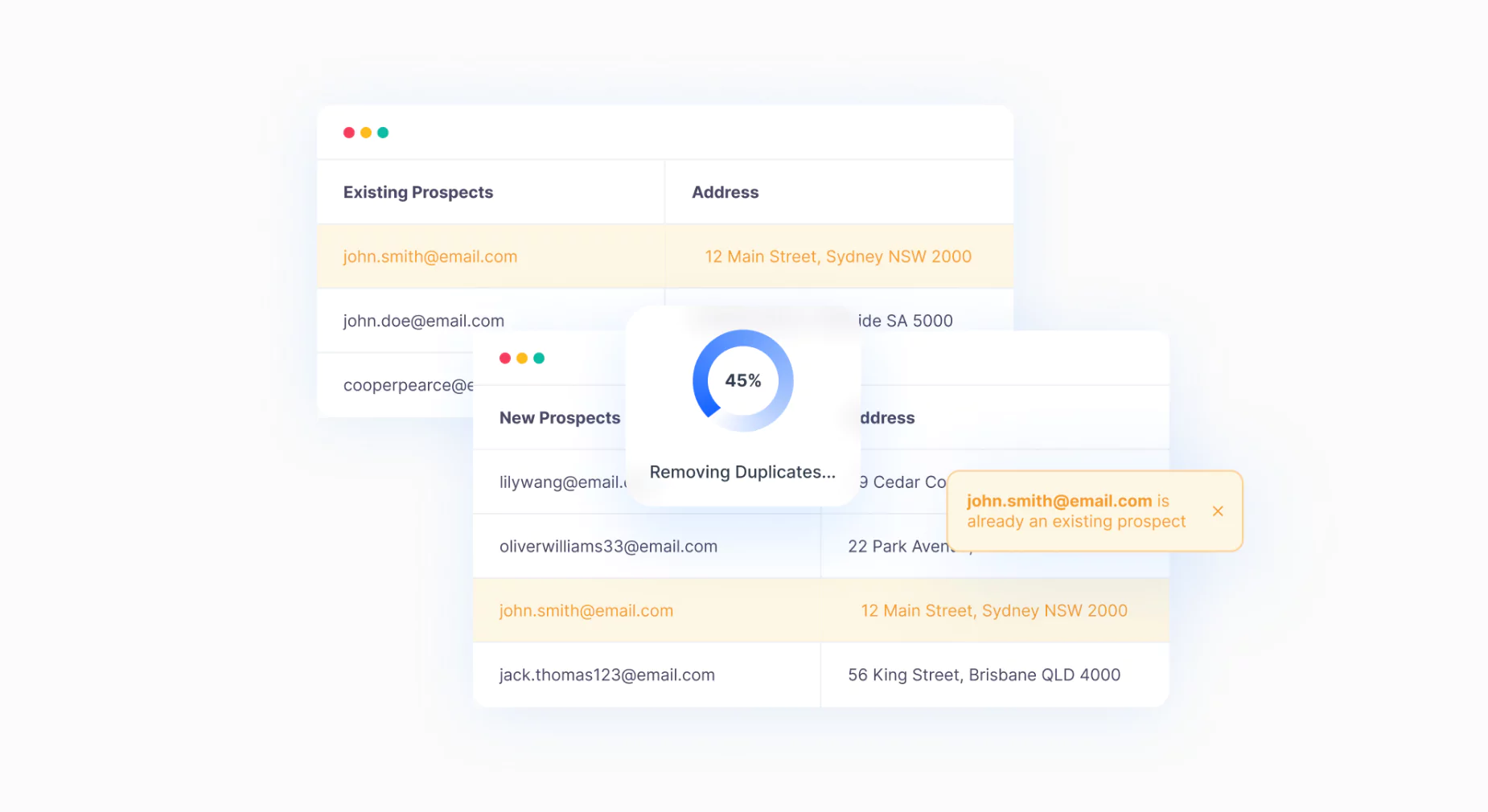
DataTools software removing duplicates from an existing database.
Key Takeaways: Data Deduplication
Looks like a lot to think about, huh? While building up to the task can require a lot of thought, the actual process isn’t complex at all. Each business scenario is different, which is why DataTools Kleber was created to allow for varying degrees of matching. Our clients have the flexibility to choose between loose to tighter matches, depending on what they need at any point in time.
So just think about your database and ask yourself: When was the last time we did a proper audit on duplicate data in the system?